11 R Módulo 2 - Importando planilhas de dados
RESUMO
A importação de planilhas do Excel para o ambiente de programação R é uma tarefa fundamental para análise de dados e estatísticas. Através da importação de planilhas do Excel, é possível transformar dados armazenados em formatos familiares em estruturas que podem ser manipuladas e exploradas de maneira eficaz no R. Isso permite a aplicação de diversas técnicas estatísticas e criação de visualizações informativas, contribuindo para a tomada de decisões embasadas em dados. Neste contexto, entender como importar dados do Excel para o R é um passo crucial para realizar análises de alta qualidade e obter insights significativos a partir dos conjuntos de dados disponíveis.
Apresentação
A importação de planilhas do Excel para o ambiente de programação R é uma tarefa fundamental para análise de dados e estatísticas. O R é uma linguagem de programação amplamente utilizada por cientistas de dados, pesquisadores e analistas para manipular, visualizar e modelar informações. Através da importação de planilhas do Excel, é possível transformar dados armazenados em formatos familiares em estruturas que podem ser manipuladas e exploradas de maneira eficaz no R. Isso permite a aplicação de diversas técnicas estatísticas e criação de visualizações informativas, contribuindo para a tomada de decisões embasadas em dados. Neste contexto, entender como importar dados do Excel para o R é um passo crucial para realizar análises de alta qualidade e obter insights significativos a partir dos conjuntos de dados disponíveis.
11.1 Sobre os dados do PPBio
Usaremos para esse tutorial dados coletados no Programa de Pesquisa em Biodiversidade - PPBio (veja Programa de Pesquisa em Biodiversidade – PPBio). Nesta base de dados estão armazenadas informações sobre diversos grupos taxonômicos dstribuidos em diversas unidades amostrais (UA’s ou sítios), como peixes, macroinverbrebrados bentônicos, quironomídeos e zooplâncotn, além de dados do habitat, como variáveis físicas e químicas, morfologia do habitat, composição do substrato, estrutura de habitat marginal, entre outros (Figura 11.1).
Essa é a matriz bruta de dados, porque os valores ainda não foram ajustados para os valores de Captura Por Unidade de Esforço (CPUE), nem foram relativizados ou transformados.
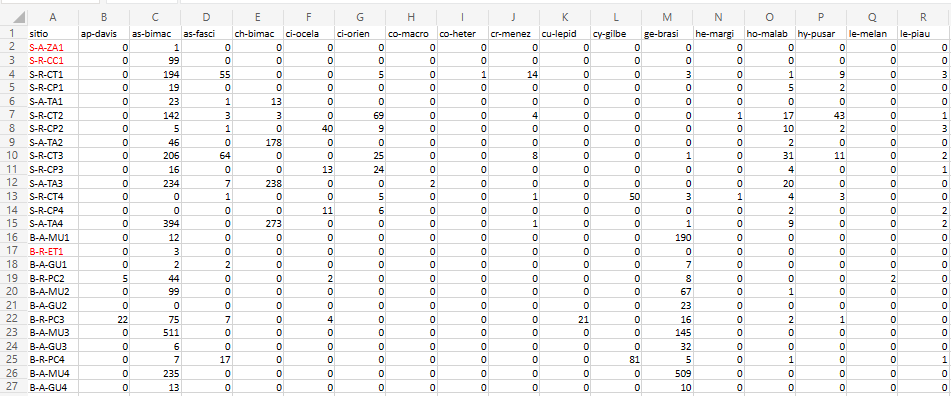
Figura 11.1: Parte da planilha de dados brutos do PPBio.
IMPORTANTE
Veja as matrizes de dados disponíveis para análises, suas descrições e tipos de dados, na seção Arquivos disponíveis do Capítulo Bases de dados.
A planilha ppbio*-peixes.*** contém o delineamento amostral de um dos estudos do Projeto PPBio (Figura 11.2). Nas linhas são apresentadas as abreviações dos nomes das unidades amostrais (UA’s) e nas colunas são apresentados os nomes abreviados das espécies - temos portando uma matriz comunitária. No corpo da planilha temos os valores para o tipo de dados amostrado. Quantitativo, semi-quatitativo ou qualitativo.
Qual desses tipos de dados você acha que é apresentado na planilha?
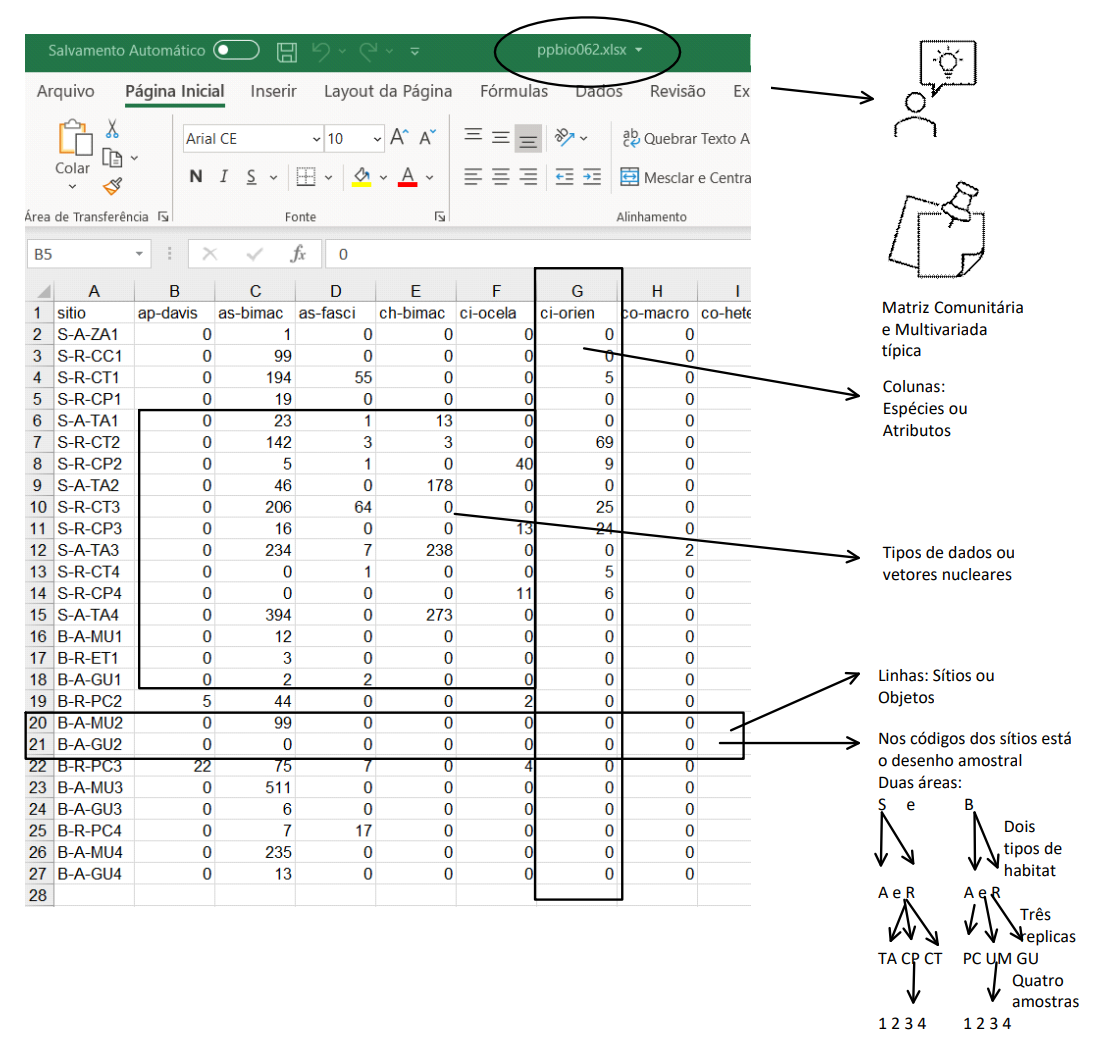
Figura 11.2: Associação entre a planilha de dados brutos do PPBio e o delineamento amostral do estudo.
Várias das espécies nessa matriz tem grande importância ecológica, como é o caso de Astyanax bimaculatus 11 (Figura 11.3), que é muito comum em rios intermitentes e serve de alimento para predadores maiores como a espécie Hoplias malabaricus 12 (Figura 11.4).

Figura 11.3: Astyanax bimaculatus, a espécie mais comum da matriz de dados ppbio. Peru, by Eakins, R. Fonte: https://www.fishbase.se/summary/Astianax-bimaculatus.html

Figura 11.4: Hoplias malabaricus, espécie que cresce para se tornar um importante predador. Brazil, by Roselet, F.F.G. Fonte: https://www.fishbase.se/summary/Hoplias-malabaricus.html
NOTA
Se você ainda não tem o R e o RStudio instalados veja a seção Instalação do R e RStudio do Capítulo Introdução ao R/RStudio
11.2 Importando a planilha de trabalho
ATENÇÃO
Os links para baixar as planilhas necessárias para repetir esse tutorial podem ser encontrados na seção Arquivos disponíveis do Capítulo Bases de dados.
Ou, baixe aqui o arquivo ppbio06c-peixes.xlsx
Para começar a usar o R e analisar os dados do Projeto PPBio, abra o RStudio, verifique sua interface e siga as instruções a seguir.
11.3 Organização básica
No ambiente do RStudio no painel de edição de código execute (Ctrl+Enter com o teclado ou Run no editor de código) os comandos a seguir, para instalar os pacotes necessários para este módulo.
install.packages("readxl") #importa arquivos do excelE em seguida,
Os códigos acima, são usados para instalar e carregar os pacotes necessários para este módulo. Esses códigos são comandos para instalar pacotes no R. Um pacote é uma coleção de funções, dados e documentação que ampliam as capacidades do R (R CRAN) (TEAM, 2022), e RStudio (R STUDIO TEAM, 2022). No exemplo acima, o pacote readxl permite ler e escrever arquivos Excel no R.
Para instalar um pacote no R, você precisa usar a função install.packages(). Depois de instalar um pacote, você precisa carregá-lo na sua sessão R com a função library().
Por exemplo, para carregar o pacote readxl, você precisa executar a função library(readxl). Isso irá permitir que você use as funções do pacote na sua sessão R. Você precisa carregar um pacote toda vez que iniciar uma nova sessão R e quiser usar um pacote instalado.
Agora vamos definir o diretório de trabalho. Esse código é usado para obter e definir o diretório de trabalho atual no R. O comando getwd() retorna o caminho do diretório onde o R está lendo e salvando arquivos. O comando setwd() muda esse diretório de trabalho para o caminho especificado entre aspas. No seu caso, você deve ajustar o caminho para o seu próprio diretório de trabalho. Lembre de usar a barra “/” entre os diretórios. E não a contra-barra “\”.
Usaremos uma matriz multivariada (sítios x espécies, matriz comunitária) do Projeto PPBio chamada ppbio**.xlsx que está no diretório “C:/Meu/Diretório/De/Trabalho/Planilha.xlsx”
Lembre que o símbolo # em programação R significa que o texto que vem depois dele é um comentário e não será executado pelo programa. Isso é útil para explicar o código ou deixar anotações.
Ajuste a segunda linha do código abaixo para refletir “C:/Seu/Diretório/De/Trabalho/Planilha.xlsx”.
Definindo o diretório de trabalho e installando os pacotes necessários:
Alternativamente você pode ir na barra de tarefas e escolhes as opções:\SESSION -> SET WORKING DIRECTORY -> CHOOSE DIRECTORY
11.4 Importando a planilha
library(readxl)
ppbio06 <- read_excel("D:/Elvio/OneDrive/Disciplinas/_EcoNumerica/5.Matrizes/ppbio06c-peixes.xlsx",
sheet = "Sheet1",
na = "NA")
str(ppbio06)
class(ppbio06)Com essas linhas de código a primeira coluna da matriz importada apresenta texto. Não queremos assim porque vamos fazer cálculos matemáticos na matriz.
Resolvemos o problema com mais algumas linhas de código.
ppbio06 <- as.data.frame(ppbio06)
class(ppbio06)
rownames(ppbio06) <- ppbio06[,1] #tem que ser um df
ppbio06[,1] <- NULLOu podemos instalar esse pacote de importação de arquivos .xlsx para o R.
install.packages("openxlsx")
library(openxlsx)
ppbio <- read.xlsx("D:/Elvio/OneDrive/Disciplinas/_EcoNumerica/5.Matrizes/ppbio06c-peixes.xlsx",
rowNames = T,
colNames = T,
sheet = "Sheet1")
str(ppbio)
class(ppbio)
ppbio_ma <- as.matrix(ppbio) #lê ppbio como uma matriz
str(ppbio_ma)
class(ppbio_ma)
#ppbio
#ppbio_maCompare as diferenças. Agora podemos exportar os dados como uma matriz de dados em formato de valores separados por vírgula (.csv).
write.table(ppbio, "ppbiocsv.txt", append = F, quote = T, ";", row.names = T)
dir <- getwd()
shell.exec(dir) #abre o diretorio de trabalho no Windows ExplorerPodemos abrir o arquivo .csv criado ppbiocsv.txt usando os códigos abaixo.
ppbiocsv <- read.csv("ppbiocsv.txt",
sep = ";", dec = ",", #definimos o dígito separador
header = T,
row.names = 1,
na.strings = NA)
str(ppbiocsv)
ppbiocsvLembre de prestar atenção no dígito separador de decimais ” , ” ou ” . ” . Além disso, só estaamos usando ppbio**.*** porque o diretório de trabalho ja fo definido no início. Se não deveríamos estar usando C:/Seu/Diretório/De/Trabalho/ppbio**.***
Alguns comandos para exibir a planilha são “case-sensitive” (ignore.case(object))
Atente para os resultados dos comandos a seguir.
#View(ppbio)
print(ppbio06[1:10, 1:10])
#ppbio
str(ppbio06)
#?str
mode(ppbio06)
#?mode
class(ppbio06)
#?class
ppbio06_ma <- as.matrix(ppbio06) #lê ppbio como uma matriz
str(ppbio06_ma)
#?View
#?view
#?remove## ap-davis as-bimac as-fasci ch-bimac ci-ocela ci-orien co-macro co-heter
## S-A-ZA1 0 1 0 0 0 0 0 0
## S-R-CC1 0 99 0 0 0 0 0 0
## S-R-CT1 0 194 55 0 0 5 0 1
## S-R-CP1 0 19 0 0 0 0 0 0
## S-A-TA1 0 23 1 13 0 0 0 0
## S-R-CT2 0 142 3 3 0 69 0 0
## S-R-CP2 0 5 1 0 40 9 0 0
## S-A-TA2 0 46 0 178 0 0 0 0
## S-R-CT3 0 206 64 0 0 25 0 0
## S-R-CP3 0 16 0 0 13 24 0 0
## cr-menez cu-lepid
## S-A-ZA1 0 0
## S-R-CC1 0 0
## S-R-CT1 14 0
## S-R-CP1 0 0
## S-A-TA1 0 0
## S-R-CT2 4 0
## S-R-CP2 0 0
## S-A-TA2 0 0
## S-R-CT3 8 0
## S-R-CP3 0 0
## 'data.frame': 26 obs. of 35 variables:
## $ ap-davis : num 0 0 0 0 0 0 0 0 0 0 ...
## $ as-bimac : num 1 99 194 19 23 142 5 46 206 16 ...
## $ as-fasci : num 0 0 55 0 1 3 1 0 64 0 ...
## $ ch-bimac : num 0 0 0 0 13 3 0 178 0 0 ...
## $ ci-ocela : num 0 0 0 0 0 0 40 0 0 13 ...
## $ ci-orien : num 0 0 5 0 0 69 9 0 25 24 ...
## $ co-macro : num 0 0 0 0 0 0 0 0 0 0 ...
## $ co-heter : num 0 0 1 0 0 0 0 0 0 0 ...
## $ cr-menez : num 0 0 14 0 0 4 0 0 8 0 ...
## $ cu-lepid : num 0 0 0 0 0 0 0 0 0 0 ...
## $ cy-gilbe : num 0 0 0 0 0 0 0 0 0 0 ...
## $ ge-brasi : num 0 0 3 0 0 0 0 0 1 0 ...
## $ he-margi : num 0 0 0 0 0 1 0 0 0 0 ...
## $ ho-malab : num 0 0 1 5 0 17 10 2 31 4 ...
## $ hy-pusar : num 0 0 9 2 0 43 2 0 11 0 ...
## $ le-melan : num 0 0 0 0 0 0 0 0 0 0 ...
## $ le-piau : num 0 0 3 0 0 1 3 0 2 1 ...
## $ le-taeni : num 0 0 0 0 0 0 0 0 0 0 ...
## $ mo-costa : num 0 0 0 0 0 0 0 0 0 0 ...
## $ mo-lepid : num 0 1 39 0 0 1 0 0 0 0 ...
## $ or-nilot : num 0 2 36 0 0 77 0 0 138 0 ...
## $ pa-manag : num 0 0 0 0 0 0 0 0 0 0 ...
## $ pimel-sp : num 0 0 6 0 0 0 0 0 0 0 ...
## $ po-retic : num 0 0 0 0 0 20 0 0 5 0 ...
## $ po-vivip : num 0 0 47 15 0 221 32 0 326 10 ...
## $ pr-brevi : num 9 0 5 0 1 15 5 2 164 0 ...
## $ ps-rhomb : num 0 0 0 0 0 0 0 0 1 0 ...
## $ ps-genise: num 0 0 0 0 0 0 0 0 1 0 ...
## $ se-heter : num 0 0 40 14 4 60 0 0 38 0 ...
## $ se-piaba : num 0 0 68 0 0 0 0 0 0 0 ...
## $ se-spilo : num 0 0 0 0 0 0 0 0 1 0 ...
## $ st-noton : num 0 0 1 0 0 25 0 0 115 0 ...
## $ sy-marmo : num 0 0 0 0 0 0 1 0 0 0 ...
## $ te-chalc : num 0 0 0 0 0 0 0 0 0 0 ...
## $ tr-signa : num 0 0 18 0 0 15 0 0 7 0 ...
## [1] "list"
## [1] "data.frame"
## num [1:26, 1:35] 0 0 0 0 0 0 0 0 0 0 ...
## - attr(*, "dimnames")=List of 2
## ..$ : chr [1:26] "S-A-ZA1" "S-R-CC1" "S-R-CT1" "S-R-CP1" ...
## ..$ : chr [1:35] "ap-davis" "as-bimac" "as-fasci" "ch-bimac" ...11.4.1 Outra forma de achar e importar uma planilha
Essa forma é desaconselhavel porque é demorada e sujeita a erros. Além de precisar ser refeita sempre que se quiser abrir uma nova planilha ou reabrir a última planilha importada.
getwd()
ppbio <- read.xlsx(file.choose(), #abre o windows explorer
rowNames = T, colNames = T,
sheet = "Sheet1")
11.5 Importando .ods do LibreOffice Calc
A planilha a seguir pode ser baixada da seção @ref(#arqs)
#install.packages("readODS")
library(readODS)
ppbio06.ods <- read_ods("D:/Elvio/OneDrive/Disciplinas/_EcoNumerica/5.Matrizes/ppbio06c-peixes.ods",
row_names = TRUE,
col_names = TRUE,
sheet = "Sheet1",
as_tibble = FALSE,
na = "n/a") # porque existem celulas vazias (n/a)
ppbio06.ods <- na.omit(ppbio06.ods)
str(ppbio06.ods)
class(ppbio06.ods)
ppbio06.ods_ma <- as.matrix(ppbio06.ods) #lê como uma matriz
str(ppbio06.ods_ma)
class(ppbio06.ods_ma)
#ppbio06.ods
#ppbio06.ods_ma11.6 Manipulando matrizes de dados
11.6.1 Colunas com o mesmo nome
Em algumas situações é necessário encontrar colunas com o mesmo nome em um conjunto de dados e soma-las ou fazer sua média. Isso pode ocorrer quando se está trabalhando com dados de várias fontes e é necessário combinar esses diferentes conjuntos de dados.
Considere por exemplo um cenário onde se está trabalhando em um projeto de análise de dados ecológicos e você recebeu conjuntos de dados de diferentes locais de amostragens enviados por diferentes pesquisadores, e cada pesquiador enviou seu conjunto de dados que contém informações sobre as mesmas espécies (ou variáveis ambientais). Devido a diferentes sistemas de registro ou a falta de comunicação entre os pesquisadores, pode haver repetição nos nomes das colunas.
#Dados de mamíferos roedores
df <- data.frame(
Rato = c(1, 2, 3),
Musaranho = c(4, 5, 6),
Rato = c(7, 8, 9), #nome duplicado
Esquilo = c(0, 0, 1),
Ratão = c(1, 1, 0),
Castor = c(1, 0, 0),
Tâmia = c(11, 12, 13),
Marmota = c(1, 2, 0),
Castor = c(2, 1, 1), #nome duplicado
check.names = FALSE
)
df## Rato Musaranho Rato Esquilo Ratão Castor Tâmia Marmota Castor
## 1 1 4 7 0 1 1 11 1 2
## 2 2 5 8 0 1 0 12 2 1
## 3 3 6 9 1 0 0 13 0 1Por exemplo, no estudo sobre mamíferos roedores acima, quando se combina o conjunto geral de dados para realizar uma análise abrangente, depara-se com colunas duplicadas, onde a matriz com o conjunto total de dados contém espécies repetidas.
Nesse caso, encontrar e resolver colunas com o mesmo nome é crucial para garantir a integridade dos dados e realizar uma análise precisa. Você deve consolidar essas colunas duplicadas, somando-as ou fazendo sua média.
# Achando colunas com nomes duplicados
dup_cols <- names(df)[duplicated(names(df))]
# Somando colunas com o mesmo nome
for (col_name in unique(dup_cols)) {
# Get indices of columns with the same name
col_indices <- which(names(df) == col_name)
# Sum columns with the same name
df[[col_name]] <- rowSums(df[, col_indices, drop = FALSE])
}
# Remove as colunas duplicadas originais e mantem as novas colunas que são a soma ("except for the first occurrence")
df <- df[, !duplicated(names(df))]
# Mostra a nova tabela com colunas repetidas somadas
print(df)## Rato Musaranho Esquilo Ratão Castor Tâmia Marmota
## 1 8 4 0 1 3 11 1
## 2 10 5 0 1 1 12 2
## 3 12 6 1 0 1 13 011.6.3 Criando uma matriz de médias
Por razões diferentes o precedimento anterior pode vir a ser necessário de ser aplicado às linhas. Por exemplo, quando se quer somar ou fazer a média de amostras diferentes do mesmo ambiente de coleta. Veja a matriz abaixo.
data <- read.table(text = "
Sp1 Sp2 Sp3 Sp4 Sp5 Sp6 Sp7 Sp8
A1 0 0 0 0 0 0 6 1
A2 0 0 0 2 0 0 10 2
B1 93 2 0 177 0 260 2 5
B2 0 4 0 8 0 0 83 7
C1 0 0 0 0 1 0 0 1
C2 0 0 1 0 0 1 0 1
C3 0 2 0 2 0 0 0 1
", header = TRUE, row.names = 1)
data## Sp1 Sp2 Sp3 Sp4 Sp5 Sp6 Sp7 Sp8
## A1 0 0 0 0 0 0 6 1
## A2 0 0 0 2 0 0 10 2
## B1 93 2 0 177 0 260 2 5
## B2 0 4 0 8 0 0 83 7
## C1 0 0 0 0 1 0 0 1
## C2 0 0 1 0 0 1 0 1
## C3 0 2 0 2 0 0 0 1
library("tidyverse")
#Inserindo coluna para agrupamentos
nrow(data); ncol(data) #no. de N colunas x M linhas
data_g <- cbind(Grupos = rownames(data), data)
data_g
grps <- substr(data_g[, 1], 1,3)
grps
data_g <- data_g %>% mutate(Grupos=c(grps))
#data_avg <- aggregate(data_g[, 9:9], list(data_g$Grupos), mean)
#data_avg
data_avg <- data_g %>%
group_by(Grupos) %>%
summarise(across(.cols = everything(), ~ mean(.x, na.rm = TRUE)))
data_avg
data_dp <- data_g %>%
group_by(Grupos) %>%
summarise(across(.cols = everything(), list(mean = mean, sd = sd)))
#?across
data_dp
#Primeira coluna para nomes das linhas
data_dp <- as.data.frame(data_dp)
class(data_dp)
rownames(data_dp) <- data_dp[,1]
data_dp[,1] <- NULL
data_dp <- round(data_dp, 1)
data_dp
#Salvando a matriz
write.table(data_dp,
"data_dp.csv",
append = F,
quote = TRUE,
sep = ";", dec = ",",
row.names = T)
data_dp_csv <- read.csv("data_dp.csv",
sep = ";", dec = ",",
header = T,
row.names = 1,
na.strings = NA)Apêndices
Sites consultados
[https://youtu.be/U6ksXvvY6Q0]
[https://youtu.be/a7EJE_2mtGk]
Script limpo
Aqui apresento o scrip na íntegra sem os textos ou outros comentários. Você pode copiar e colar no R para executa-lo. Lembre de remover os # ou ## caso necessite executar essas linhas.
## install.packages("readxl") #importa arquivos do excel
## library(readxl)
## getwd()
## setwd("C:/Seu/Diretório/De/Trabalho")
library(readxl)
ppbio06 <- read_excel("D:/Elvio/OneDrive/Disciplinas/_EcoNumerica/5.Matrizes/ppbio06.xlsx",
sheet = "Sheet1",
na = "NA")
str(ppbio06)
class(ppbio06)
ppbio06 <- as.data.frame(ppbio06)
class(ppbio06)
rownames(ppbio06) <- ppbio06[,1] #tem que ser um df
ppbio06[,1] <- NULL
#install.packages("openxlsx")
library(openxlsx)
ppbio <- read.xlsx("D:/Elvio/OneDrive/Disciplinas/_EcoNumerica/5.Matrizes/bentos06.xlsx",
rowNames = T,
colNames = T,
sheet = "contagem")
str(ppbio)
class(ppbio)
ppbio_ma <- as.matrix(ppbio) #lê ppbio como uma matriz
str(ppbio_ma)
class(ppbio_ma)
#ppbio
#ppbio_ma
## write.table(ppbio, "ppbiocsv.txt", append = F, quote = T, ";", row.names = T)
## dir <- getwd()
## shell.exec(dir) #abre o diretorio de trabalho no Windows Explorer
## ppbiocsv <- read.csv("ppbiocsv.txt",
## sep = ";", dec = ",", #definimos o dígito separador
## header = T,
## row.names = 1,
## na.strings = NA)
## str(ppbiocsv)
## ppbiocsv
## #View(ppbio)
## print(ppbio)
## ppbio
## str(ppbio)
## #?View
## #?view
## #?remove
## getwd()
## ppbio <- read.xlsx(file.choose(), #abre o windows explorer
## rowNames = T, colNames = T,
## sheet = "Sheet1")